install.packages(c("ds4psy", "lintr", "usethis", "devtools","roxygen2"))Clean Code, Reproducible Science: Advanced R-Programming and Workflows
Part 1
13.05.2026
Housekeeping
All materials for the workshop (slides, scripts, references) can be found on this website:
http://www.johannesfeldhege.de/peergroup_workshop/

It is hosted on Github with a permissive license so you can use them however you want.
Results from the pre-workshop survey
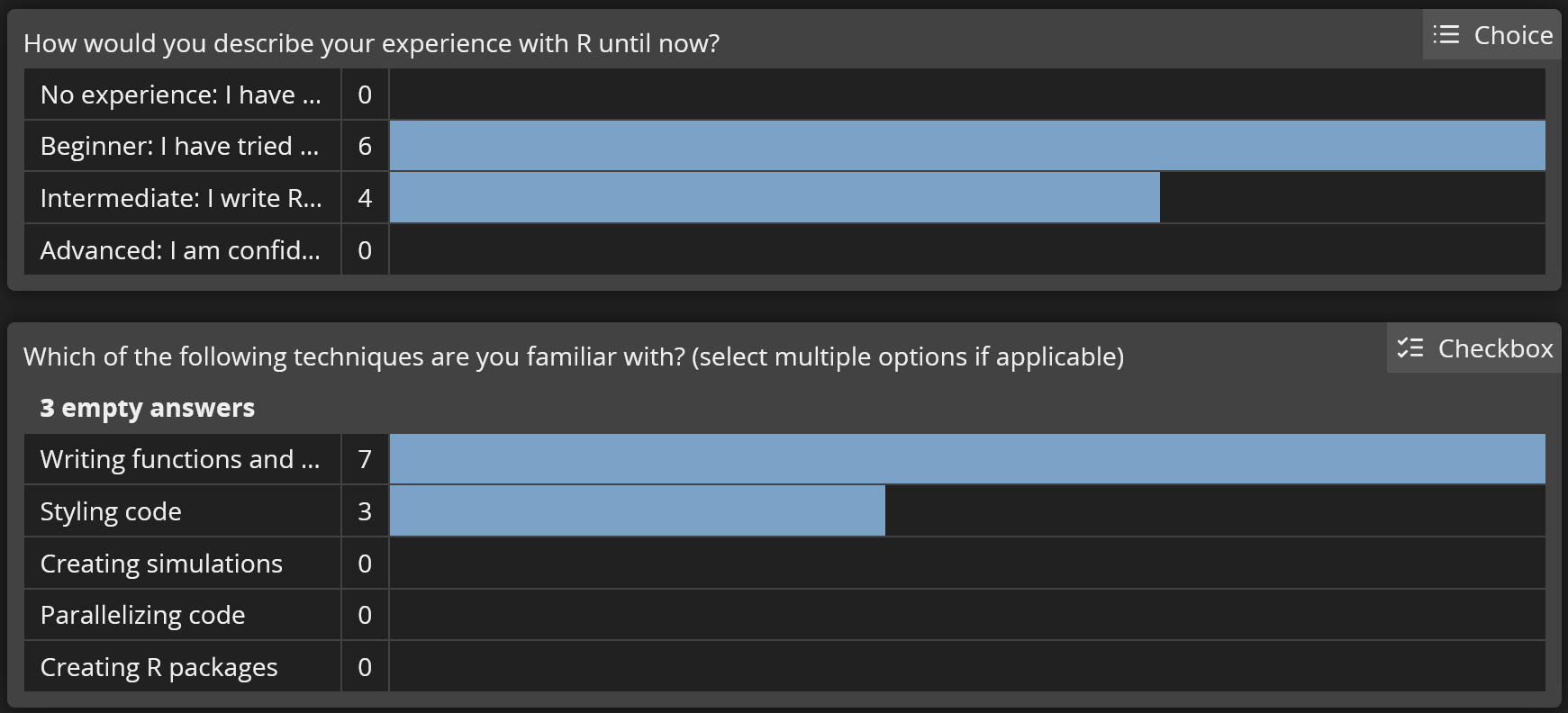
Experience with R
Results from the pre-workshop survey
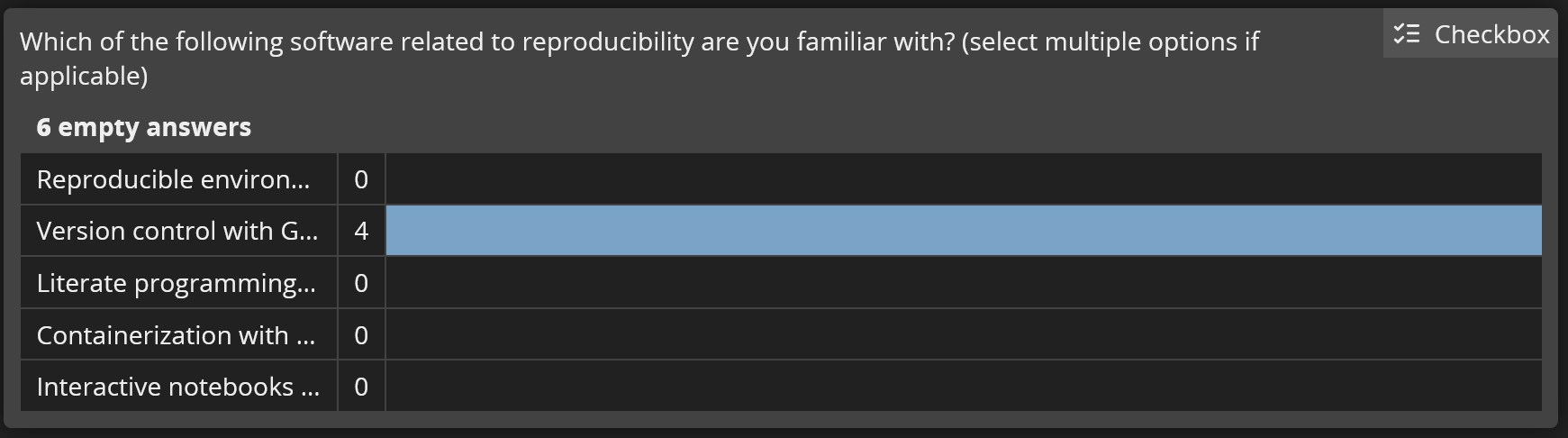
Experience with reproducibility tools
Results from the pre-workshop survey

Comments
Naming things
Naming things is hard - so hard that books are written about it:

Styling code with lintr
lintr is a package for static code analysis on your R files.
Basic usage:
With code:
# Style one file
lintr::lint(path = "path/to/file")
# A whole directory or R project
lintr::lint_dir(path = "path/to/project")Or with an RStudio addin:
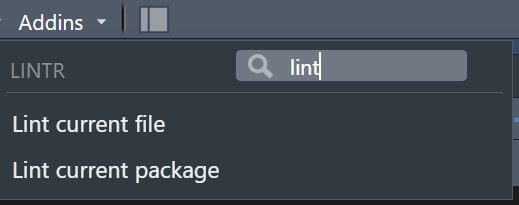
Beyond lintr
lintr gives recommendations but leaves it up to you to make changes in the code.
These tools can style your code by changing the code when executed:
Warning
Caution: these tools change your code without asking!
Never let Rstudio save anything!
Do not rely on .RData to bail you out. Either save interim datasets to files or write your script in a way that lets you start from scratch every time.
Two alternatives:
Change the RStudio options: 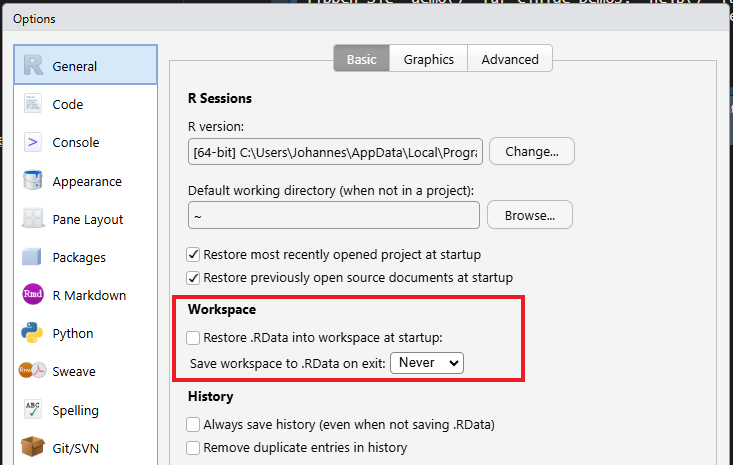
Use this function from the usethis package:
usethis::use_blank_slate()The renv package
![]()
renv controls in the computational environment:
- Specific packages and their version
- version
- operating system ( , , )
- system dependencies
Initialise renv with renv::init()
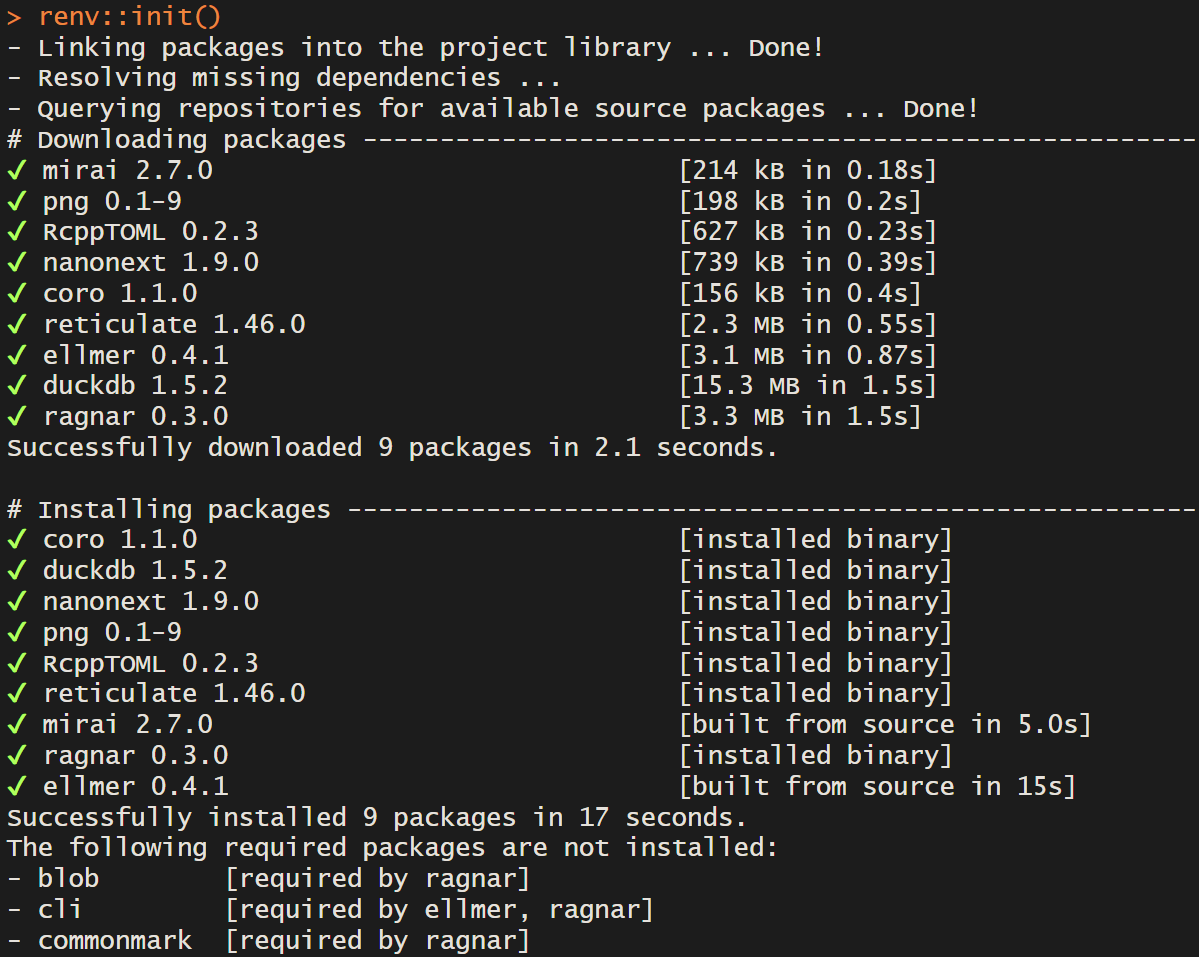
Console output after renv::init()