quarto checkClean Code, Reproducible Science: Advanced R-Programming and Workflows
Part 2
13.05.2026
Creating a Quarto document
In the RStudio menu:
File
New file
Quarto Document…
Source vs Visual Editor
You can switch between source and a visual editor when writing your Quarto document.

In visual editor mode, you get a preview of your document. It is a more beginner-friendly mode as you get a more immediate feedback on your inputs.
Switching between both modes can sometimes introduce unintended changes in the document!
Visual Editor mode
In Visual Editor mode, you can select and insert formatting or special inputs using the dropdown menus:
Rendering a document
To turn a Quarto document into the desired output format, it needs to be rendered.
This can be done using RStudio buttons:

or in the terminal:
quarto render my_quarto_file.qmdor in R with the quarto package:
quarto::render("my_quarto_file.qmd")R packages in a reproducibility context

Packages are the fundamental units of reproducible R code. They include reusable R functions, the documentation that describes how to use them, and sample data.
- Wickham and Bryan, 2023
Two essential packages
![]()
![]()
devtools: Essential functions for documenting code and building the package.
usethis: Convenience function to automate the workflow of creating a package.
The DESCRIPTION

Documenting functions with roxygen2
![]()
The idea behind roxygen2 is to document functions with special comments next to their definition. roxygen2 will process these comments and turn them into manual pages in the package.
You can add a comment skeleton with control + alt + shift + R when your cursor is inside the function.
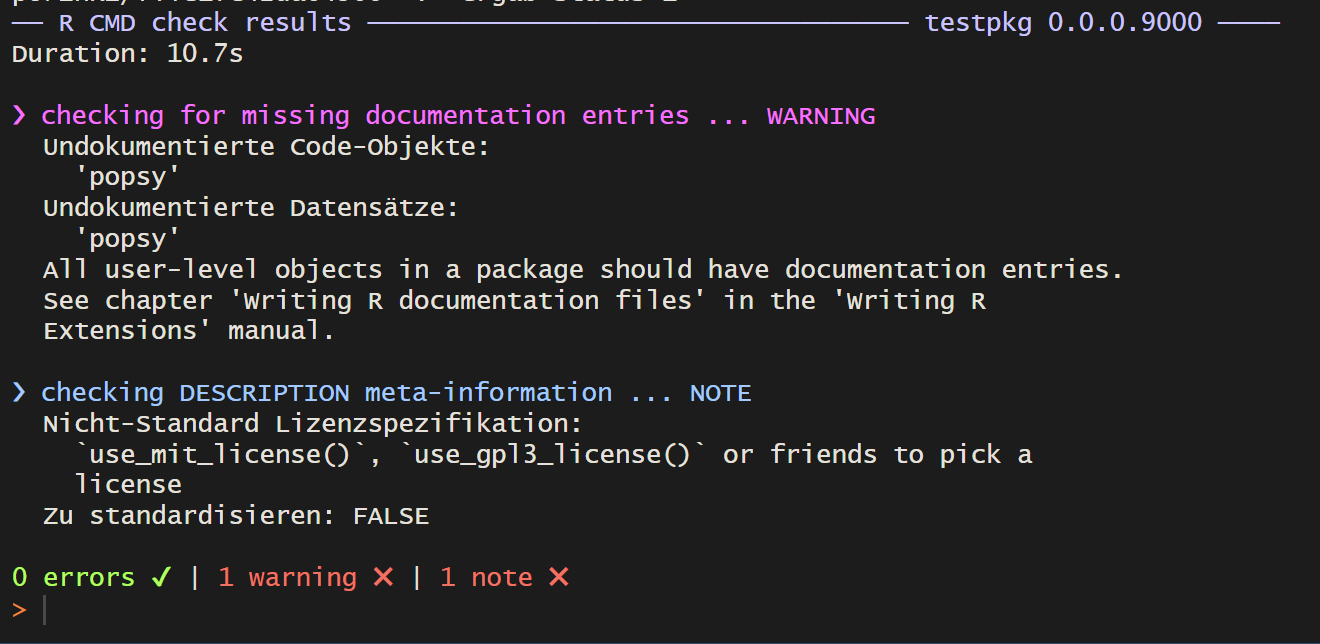
R CMD Check
R CMD check runs checks intended for publication on CRAN. Its output gives strict feedback:
errors need to be fixed
warnings affect functionality
notes can often be ignored if you do not intend to publish the package on CRAN
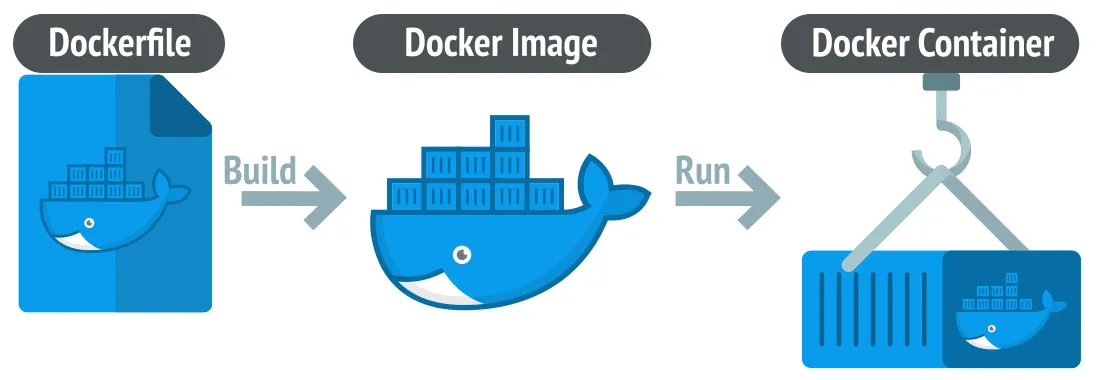
What is an image?
An image is a package that contains all necessary instructions to create a container.
The specifications for an image is defined in a text file, e.g. a Docker file:
- what operating system is needed
- what software needs to be installed